Welcome to the final module of our comprehensive study of Ridge Regression!
In Module 1, we uncovered various facets of Ridge Regression, starting with SVD (Singular Value Decomposition) approach. We carefully dissected the formula for the Ridge estimator: 
Our previous discussions in Module 2 illuminated the mean and variance of 
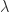
Now, we are set to cover another method of determining the Ridge estimator. We’ll pivot from the previously discussed methods and delve into the realm of Bayesian statistics, particularly focusing on MAP (Maximum A Posteriori) Estimation. This approach refines the MLE (Maximum Likelihood Estimation) methodology by integrating a prior distribution 
To set the stage, let’s briefly revisit the MLE approach. The MLE method for deducing the weights is framed as:

This equation represents the cornerstone of likelihood–based estimation, seeking the weight vector 


Using MAP Estimation
The MAP approach incorporates prior beliefs about the distribution of the weights through 
Our goal is to determine 

This equation might seem daunting, but we can rewrite it using Bayes’ Theorem:

where 


Let’s assume our response variable 




Our expanded expression for the MAP estimator is given by:

In this expression, the terms 


applying the logarithm trick for simplification, our expression becomes a problem of minimization:

Expanding and rearranging the terms, we have:

As this function is convex in

After computing the gradient and simplifying, we arrive at:

therefore, our Ridge Estimator, by re-arranging and solving for

This derivation not only reinforces our understanding of the Ridge Estimator but also highlights the seamless blend of statistical theory and mathematical elegance inherent in Ridge Regression.
