With a clear understanding of the framework of Ridge Regression, we are now well-equipped to delve deeper into some of its nuances. A key aspect of this exploration involves examining the parameters of the distribution over the Ridge weights, denoted as  . Through this, we will uncover a crucial property: while Ridge Regression helps mitigate high variance in our OLS model, it also potentially introduces a significant amount of bias. This emphasizes the necessity to develop methods that can optimize the trade-off between bias and variance, which we will investigate later. For now, it is important to learn about some already established preliminary results concerning our response variable
. Through this, we will uncover a crucial property: while Ridge Regression helps mitigate high variance in our OLS model, it also potentially introduces a significant amount of bias. This emphasizes the necessity to develop methods that can optimize the trade-off between bias and variance, which we will investigate later. For now, it is important to learn about some already established preliminary results concerning our response variable  .
.
Understanding y
Before we proceed to determine the parameters for the distribution over , we will take a moment to reexamine and clarify the nature of . This reexamination will ensure that we have a comprehensive understanding of as a fundamental element in our analysis, setting the stage for a more informed exploration of the distribution parameters of Ridge weights. Lets revisit the first two fundamental assumptions about Linear Regression:
Linearity Assumption: This implies that the relationship between the dependent variable and the independent variables  is linear, represented as:
is linear, represented as:

Homoscedasticity: This term refers to the assumption that the residuals (or errors)  have a constant variance, denoted as:
have a constant variance, denoted as:

By combining these assumptions, we arrive at an important inference that has been commonly stated. The distribution of can be modeled as a normal distribution with mean  and a variance of
and a variance of  expressed as:
expressed as:  .
.
It’s also pertinent to reintroduce an equation from my previous discussion on the Ordinary Least Squares (OLS) estimator:
![\mathbb{E}[yy^{T}] = \sigma^{2} I + Xww^{T}X^{T}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Byy%5E%7BT%7D%5D+%3D+%5Csigma%5E%7B2%7D+I+%2B+Xww%5E%7BT%7DX%5E%7BT%7D&bg=ffffff&fg=242424&s=0&c=20201002)
This equation, derived from a detailed examination of the variance of , provides valuable insights into our evaluation of the variance of .
Evaluating the Mean
Following the same approach we used to determine the expected value of  , we will set up the calculation for in a similar manner:
, we will set up the calculation for in a similar manner:
![\mathbb{E}[w_{Ridge}] = \mathbb{E}[(X^{T}X + \lambda I)^{-1}X^{T}y]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bw_%7BRidge%7D%5D+%3D+%5Cmathbb%7BE%7D%5B%28X%5E%7BT%7DX+%2B+%5Clambda+I%29%5E%7B-1%7DX%5E%7BT%7Dy%5D&bg=ffffff&fg=242424&s=0&c=20201002)
![= (X^{T}X + \lambda I)^{-1}X^{T}\mathbb{E}[y]](https://s0.wp.com/latex.php?latex=%3D+%28X%5E%7BT%7DX+%2B+%5Clambda+I%29%5E%7B-1%7DX%5E%7BT%7D%5Cmathbb%7BE%7D%5By%5D&bg=ffffff&fg=242424&s=0&c=20201002)

So we observe that as 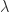 approaches zero,
approaches zero, ![\mathbb{E}[w_{Ridge}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bw_%7BRidge%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002) converges towards
converges towards ![\mathbb{E}[w_{LS}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bw_%7BLS%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002) . On the other hand, when increases towards infinity, tends toward zero. It’s important to note here that with any positive value of , there is an inherent addition of bias to the Ridge weights.
. On the other hand, when increases towards infinity, tends toward zero. It’s important to note here that with any positive value of , there is an inherent addition of bias to the Ridge weights.
Evaluating the Variance
We’ve seen how incorporating the ridge term introduces additional bias into the weights of our model. While increasing bias is generally undesirable, understanding the full impact of this modification is essential. Specifically, we need to examine how the variance of is affected by the addition of the ridge term.
Remembering our earlier analyses, we deduced that ![\text{Var}[w_{LS}] = \sigma^{2}(X^{T}X)^{-1}](https://s0.wp.com/latex.php?latex=%5Ctext%7BVar%7D%5Bw_%7BLS%7D%5D+%3D+%5Csigma%5E%7B2%7D%28X%5E%7BT%7DX%29%5E%7B-1%7D&bg=ffffff&fg=242424&s=0&c=20201002) , which highlighted how multicollinearity in could lead to instability in the
, which highlighted how multicollinearity in could lead to instability in the  component, raising issues in estimating variance accurately. We’ll approach the variance of
component, raising issues in estimating variance accurately. We’ll approach the variance of ![\text{Var}[w_{Ridge}]](https://s0.wp.com/latex.php?latex=%5Ctext%7BVar%7D%5Bw_%7BRidge%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002) using a similar method:
using a similar method:
![\text{Var}[w_{Ridge}] = \mathbb{E}[w_{Ridge}w_{Ridge}^{T}] - \mathbb{E}[w_{Ridge}] \mathbb{E}[w_{Ridge}^{T}]](https://s0.wp.com/latex.php?latex=%5Ctext%7BVar%7D%5Bw_%7BRidge%7D%5D+%3D+%5Cmathbb%7BE%7D%5Bw_%7BRidge%7Dw_%7BRidge%7D%5E%7BT%7D%5D+-+%5Cmathbb%7BE%7D%5Bw_%7BRidge%7D%5D+%5Cmathbb%7BE%7D%5Bw_%7BRidge%7D%5E%7BT%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002)
Lets separate this problem by terms. In term one, we have
![\mathbb{E}[w_{Ridge}w_{Ridge}^{T}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bw_%7BRidge%7Dw_%7BRidge%7D%5E%7BT%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002)
![= \mathbb{E}[(X^{T}X + \lambda I)^{-1}X^{T}yy^{T}X(X^{T}X + \lambda I)^{-1}]](https://s0.wp.com/latex.php?latex=%3D+%5Cmathbb%7BE%7D%5B%28X%5E%7BT%7DX+%2B+%5Clambda+I%29%5E%7B-1%7DX%5E%7BT%7Dyy%5E%7BT%7DX%28X%5E%7BT%7DX+%2B+%5Clambda+I%29%5E%7B-1%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002)
![= (X^{T}X + \lambda I)^{-1}X^{T} \mathbb{E}[yy^{T}]X(X^{T}X + \lambda I)^{-1}](https://s0.wp.com/latex.php?latex=%3D+%28X%5E%7BT%7DX+%2B+%5Clambda+I%29%5E%7B-1%7DX%5E%7BT%7D+%5Cmathbb%7BE%7D%5Byy%5E%7BT%7D%5DX%28X%5E%7BT%7DX+%2B+%5Clambda+I%29%5E%7B-1%7D&bg=ffffff&fg=242424&s=0&c=20201002)
by linearity of expectation. Substituting for ![\mathbb{E}[yy^{T}]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Byy%5E%7BT%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002) ,
,


This may at first seem intricate, but calculating the second term will help in simplifying the overall equation.
![\mathbb{E}[w_{Ridge}] \mathbb{E}[w_{Ridge}]^{T} = (X^{T}X + \lambda I)^{-1} X^{T}Xww^{T}X^{T}X(X^{T}X + \lambda I)^{-1}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5Bw_%7BRidge%7D%5D+%5Cmathbb%7BE%7D%5Bw_%7BRidge%7D%5D%5E%7BT%7D+%3D+%28X%5E%7BT%7DX+%2B+%5Clambda+I%29%5E%7B-1%7D+X%5E%7BT%7DXww%5E%7BT%7DX%5E%7BT%7DX%28X%5E%7BT%7DX+%2B+%5Clambda+I%29%5E%7B-1%7D&bg=ffffff&fg=242424&s=0&c=20201002)
This calculation allows us to refine and clarify our formula for the variance of :
![\text{Var}[w_{Ridge}] = \sigma^{2} \{(X^{T}X +\lambda I)^{-1}X^{T}X(X^{T}X + \lambda I)^{-1}\}](https://s0.wp.com/latex.php?latex=%5Ctext%7BVar%7D%5Bw_%7BRidge%7D%5D+%3D+%5Csigma%5E%7B2%7D+%5C%7B%28X%5E%7BT%7DX+%2B%5Clambda+I%29%5E%7B-1%7DX%5E%7BT%7DX%28X%5E%7BT%7DX+%2B+%5Clambda+I%29%5E%7B-1%7D%5C%7D&bg=ffffff&fg=242424&s=0&c=20201002)
As approaches zero, the variance of the Ridge estimator converges to the variance of the Ordinary Least Squares (OLS) estimator. Moreover as the value of increases towards infinity, the variance of the ridge regression coefficients approaches zero. This trend is due to the inversely proportional relationship between  and .
and .
Propagation of Uncertainty
A fascinating alternative to examine the variance of the ridge estimator, , is by employing the concept of uncertainty propagation. This method is particularly effective in the context of linear equations. For some  matrix
matrix  , consider the system:
, consider the system:

In such a system, the uncertainty propagation principle allows us to determine the covariance matrix of  , denoted as
, denoted as  , using the formula:
, using the formula:

This principle can be applied to our ridge estimator, which is expressed as:

We can rewrite it as  , where
, where  represents the transformation matrix
represents the transformation matrix  . This transformation takes the vector into the space of .
. This transformation takes the vector into the space of .
Assuming the covariance of the response vector is given by  , which indicates that the observations in have uniform variance
, which indicates that the observations in have uniform variance  , we can then apply the uncertainty propagation. It leads us to the variance of as follows:
, we can then apply the uncertainty propagation. It leads us to the variance of as follows:
![\text{Var}[w_{Ridge}] = Q \Sigma^{y} Q^{T}](https://s0.wp.com/latex.php?latex=%5Ctext%7BVar%7D%5Bw_%7BRidge%7D%5D+%3D+Q+%5CSigma%5E%7By%7D+Q%5E%7BT%7D&bg=ffffff&fg=242424&s=0&c=20201002)
By substituting the expressions for and  , we get
, we get
This result beautifully summarizes the influence of the response variable’s intrinsic variance, denoted as , on the variance of the ridge estimator. By understanding these crucial aspects of ’s distribution, we’ve laid a solid foundation for what’s next. Moving to Module 3 of Ridge Regression, we’ll delve into an intriguing technique known as Maximum a Posteriori (MAP) estimation, offering a fresh perspective on our ongoing analysis.
