This document is part of a developing theoretical framework authored by Christopher Lee Burgess.
Abstract
Classical variance is insufficient for characterizing the geometric structure of multimodal data. In this work, we will define a new quantity called the pseudovariance, and demonstrate how it captures shape, modality, and dispersion through a general class of functions we call “forma”. By contrasting this novel interpretation of variance with classical variance, we reveal how non-localized behavior forces us to tweak the traditional axiomatic framework. From this, we will provide a closed analytic form for multimodal distributions and demonstrate how it corresponds with other members of the exponential family. Finally, we will explore the rich connections between pseudovariance and unimodal moment behavior.
Key Words: Pseudovariance, Multimodal, Variance, Analytic Form.
Introduction
It is sort of ironic, that there has been significant variation in our formulation of variance in many chapters of statistical lineage. For now, we will focus on the one-dimensional case. If we define the mapping 



![\displaystyle \text{VAR}(X) = \mathbb{E}[\phi(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctext%7BVAR%7D%28X%29+%3D+%5Cmathbb%7BE%7D%5B%5Cphi%28X%29%5D&bg=ffffff&fg=242424&s=0&c=20201002)
where the parameter ![\mu = \mathbb{E}[X]](https://s0.wp.com/latex.php?latex=%5Cmu+%3D+%5Cmathbb%7BE%7D%5BX%5D&bg=ffffff&fg=242424&s=0&c=20201002)

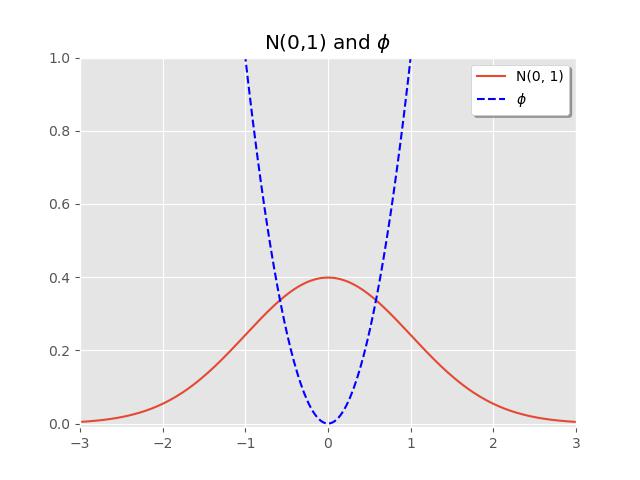
From this, we can interpret that the farther out a sampled data point 

Historically classical variance has been shown to satisfy a certain set of preliminary axioms and assumptions, enumerated below:
Axiom 0
If our random variable 


Axiom 1
(Positivity)
If 

Assumption 0
(Localization Invariance)
For any constant 

Assumption 1
For any constant 
However, one key point of this article, is that classical variance inherently assumes a unimodal central tendency and does not fully characterize the spread for multimodal distributions. To provide an example, we define the distribution 



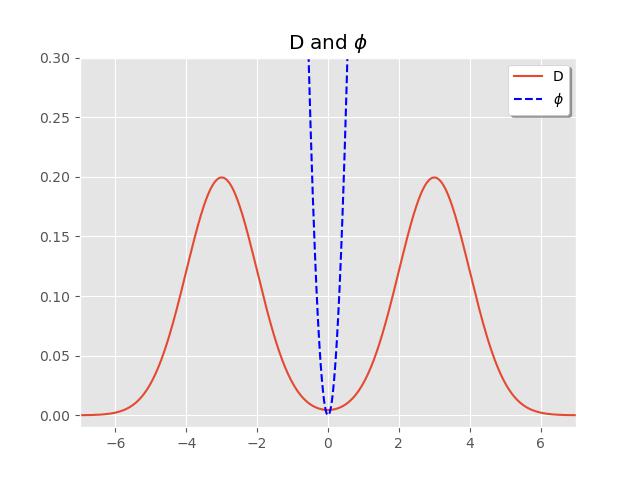
On first glance, given the shape of this bimodal distribution, we can guess that 

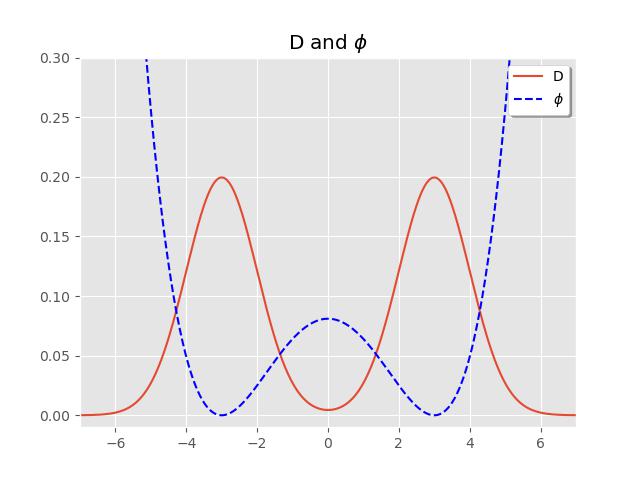
We can see how, by letting
On Pseudovariance
To formalize these concepts related to pseudovariance and multimodal distributions, I’ll first introduce a few definitions:
Definition 1 (Pseudovariance) Given some distribution 

![\displaystyle \Sigma_{\phi} = \text{VAR}_{\phi}(X) = \mathbb{E}[\phi(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CSigma_%7B%5Cphi%7D+%3D+%5Ctext%7BVAR%7D_%7B%5Cphi%7D%28X%29+%3D+%5Cmathbb%7BE%7D%5B%5Cphi%28X%29%5D&bg=ffffff&fg=242424&s=0&c=20201002)
And we will refer to 
Definition 2 (Pseudocovariance) Let 


![\displaystyle \text{COV}_{\phi}(X, Y) = \mathbb{E}[\phi(X,Y)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Ctext%7BCOV%7D_%7B%5Cphi%7D%28X%2C+Y%29+%3D+%5Cmathbb%7BE%7D%5B%5Cphi%28X%2CY%29%5D&bg=ffffff&fg=242424&s=0&c=20201002)
Definition 3 (Local Minimum) For any smooth function 




Definition 4 (Pseudomean) Given any pseudovariance 

So for example,
In the standard unimodal case, we let 
Or in the standard bimodal case, where if we let 

In this treatise, we might later consider those critical points of the forma function which are not local minima, but for now let’s move into moments.
For any positive integer 

Definition 5. (Moments) Let
![\displaystyle \mu_{k} := \frac{k!}{2}\mathbb{E}[\phi^{(2-k)}(X)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmu_%7Bk%7D+%3A%3D+%5Cfrac%7Bk%21%7D%7B2%7D%5Cmathbb%7BE%7D%5B%5Cphi%5E%7B%282-k%29%7D%28X%29%5D&bg=ffffff&fg=242424&s=0&c=20201002)
So in the classical framework, by letting our forma function be 
![\displaystyle \mu_{3} = \frac{3!}{2}\mathbb{E}[\phi^{-1}(X)] = \frac{3!}{2}\mathbb{E}[\frac{1}{3}(X - \mu)^{3}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmu_%7B3%7D+%3D+%5Cfrac%7B3%21%7D%7B2%7D%5Cmathbb%7BE%7D%5B%5Cphi%5E%7B-1%7D%28X%29%5D+%3D+%5Cfrac%7B3%21%7D%7B2%7D%5Cmathbb%7BE%7D%5B%5Cfrac%7B1%7D%7B3%7D%28X+-+%5Cmu%29%5E%7B3%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002)
![\displaystyle = \mathbb{E}[(X - \mu)^{3}]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%3D+%5Cmathbb%7BE%7D%5B%28X+-+%5Cmu%29%5E%7B3%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002)
which aligns with the classical interpretation of the 

Definition 6 (Center translation of forma) Let

and we denote by 
![\displaystyle \Sigma_{\phi_{c}} := \mathbb{E}[\phi(X - c)]](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5CSigma_%7B%5Cphi_%7Bc%7D%7D+%3A%3D+%5Cmathbb%7BE%7D%5B%5Cphi%28X+-+c%29%5D&bg=ffffff&fg=242424&s=0&c=20201002)
This construction allows us to define a modal center of a distribution. For example, if 

This shifts the modal structure
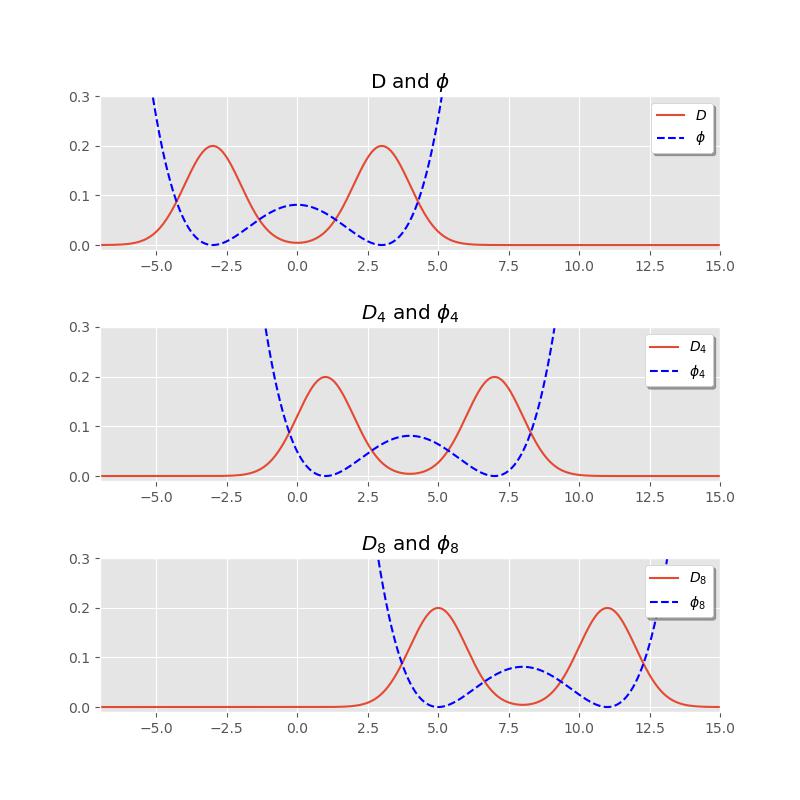
Interpreting Mixtures (Universally)
Now that we have outlined pseudovariance and the forma function, we should cover the classical interpretation of multimodal distributions, i.e. mixtures, and show how these models can be rephrased in a manner that it is shown they must be members of the exponential family of distributions.
Definition 7 (Mixtures) For 




such that 

In this case we say that 
Note: The following theorems merit further considerations in the theory of approximations.
Theorem 1. Let 

Theorem 2. (Universal Modal Approximation) Let 


such that

and

Definition 8 (Dense in a Space)
So then it is worth considering which representation is more expressive? If we let 


and

where 
Corollary 1. Let 



and

Additional items (toolbox)
Definition. (Affine Even) The set of functions 


Definition. A differentiable function
Reinterpreting Von Mises with Pseudovariance
To better understand the potential applications of pseudovariance, let’s first consider the unimodal case. While the Gaussian distribution provides a degenerate example, where the pseudovariance collapses to classical variance, it offers limited insight into the behavior of our generalization. Thus, we can use a more geometrically nuanced distribution: the Von Mises distribution. Often regarded as the circular analogue of the Gaussian, the Von Mises essentially “wraps” the normal distribution around the unit circle.
Its probability density function is defined as follows:
Links:
OSF Link:
