In our previous discussions about Linear Regression (and the OLS Estimator), we identified a key limitation: multicollinearity. When the predictor variables (columns of  ) are highly correlated, the matrix
) are highly correlated, the matrix  becomes nearly singular, affecting the stability of our OLS estimator. Ridge Regression effectively addresses the limitations of OLS regression by incorporating a parameter
becomes nearly singular, affecting the stability of our OLS estimator. Ridge Regression effectively addresses the limitations of OLS regression by incorporating a parameter 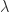 (lambda), called the Ridge parameter. This inclusion enhances the stability of
(lambda), called the Ridge parameter. This inclusion enhances the stability of  , and crucially reduces the variance of our model at the expense of introducing some bias. However before delving into the advantages of Ridge Regression over Linear Regression, it’s essential to lay some theoretical groundwork.
, and crucially reduces the variance of our model at the expense of introducing some bias. However before delving into the advantages of Ridge Regression over Linear Regression, it’s essential to lay some theoretical groundwork.
SVD Approach
One fundamental aspect of understanding Ridge Regression lies in examining the Singular Value Decomposition (SVD) of the matrix . Grasping the role of SVD here is pivotal, as it provides deep insights into how Ridge Regression stabilizes the solutions, dealing with issues like multicollinearity and overfitting, which often plague standard OLS models. SVD breaks down the matrix into three components:  ,
,  , and
, and  . Here and are unitary matrices, and is a diagonal matrix of singular values of . In this context,
. Here and are unitary matrices, and is a diagonal matrix of singular values of . In this context,  .
.
As was stated before, highly correlated columns of can lead to issues when calculating the OLS estimator, specifically in inverting . In this case, the determinant of , denoted as  , is approximately zero. Furthermore,
, is approximately zero. Furthermore,  is close to zero. Matrices with determinants that are nearly zero pose significant challenges with stable inversion. A nearly singular matrix , in the presence of multicollinearity, is sensitive to small changes in its elements. This sensitivity means that minor fluctuations in data can lead to large variations in the computed inverse, which in turn significantly affects the estimated regression coefficients. In simpler terms, matrices with determinants close to zero pose challenges in computing solutions using OLS methods.
is close to zero. Matrices with determinants that are nearly zero pose significant challenges with stable inversion. A nearly singular matrix , in the presence of multicollinearity, is sensitive to small changes in its elements. This sensitivity means that minor fluctuations in data can lead to large variations in the computed inverse, which in turn significantly affects the estimated regression coefficients. In simpler terms, matrices with determinants close to zero pose challenges in computing solutions using OLS methods.
We tackle this issue by adding an adjustable term  to
to  in the decomposition of , where
in the decomposition of , where  is the identity matrix. This adjustment changes the determinant calculation
is the identity matrix. This adjustment changes the determinant calculation  to
to  . Expanding this, we get:
. Expanding this, we get:

and since is an orthogonal matrix,  equals :
equals :

 .
.
As increases, the determinant significantly differs from zero, which ensures that  is stable. This leads us to an adjustably stable estimator of our weights:
is stable. This leads us to an adjustably stable estimator of our weights:
 .
.
Calculus-Based Solution
Traditionally, Ridge Regression is formulated through the lens of the least squares method, enhanced with the regularization term  . This approach aims to mitigate the excessive variance often observed in the OLS model. The mathematical representation is:
. This approach aims to mitigate the excessive variance often observed in the OLS model. The mathematical representation is:

To delve deeper, we can expand and simplify this equation, mirroring the process used in Linear Regression:



To find the solution to this convex problem, we set its gradient,  , equal to zero:
, equal to zero:

 ,
,
which leads us back to the previously stated solution for  :
:
 .
.
This derivation not only demonstrates the close relationship between Ridge Regression and OLS but also highlights the impact of the regularization term in refining the model.
On Degrees of Freedom
Lets observe the meaning of in terms of what is happening to the predictors (or columns) of . Again, assuming is a k – by – (d+1) matrix, we know the hat matrix

projects the response variable  onto the space of fitted values
onto the space of fitted values  . Assuming the columns of are linearly independent, one can see the rank of
. Assuming the columns of are linearly independent, one can see the rank of  is equal to the number of features of . Also, by taking the trace of :
is equal to the number of features of . Also, by taking the trace of :
![\text{trace}[H_{LS}] = \text{trace}[X(X^{T}X)^{-1}X^{T}]](https://s0.wp.com/latex.php?latex=%5Ctext%7Btrace%7D%5BH_%7BLS%7D%5D+%3D+%5Ctext%7Btrace%7D%5BX%28X%5E%7BT%7DX%29%5E%7B-1%7DX%5E%7BT%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002)
![= \text{trace}[(X^{T}X)^{-1}X^{T}X]](https://s0.wp.com/latex.php?latex=%3D+%5Ctext%7Btrace%7D%5B%28X%5E%7BT%7DX%29%5E%7B-1%7DX%5E%7BT%7DX%5D&bg=ffffff&fg=242424&s=0&c=20201002)
![= \text{trace}[I]](https://s0.wp.com/latex.php?latex=%3D+%5Ctext%7Btrace%7D%5BI%5D&bg=ffffff&fg=242424&s=0&c=20201002)

So we can see ![\text{trace}[H_{LS}]](https://s0.wp.com/latex.php?latex=%5Ctext%7Btrace%7D%5BH_%7BLS%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002) is equal to the number of predictors of , when is feasible. In the case of multicollinearity, we can modify the hat matrix:
is equal to the number of predictors of , when is feasible. In the case of multicollinearity, we can modify the hat matrix:

and observe the following equation
![df_{X}(\lambda) = \text{trace}[H_{Ridge}]](https://s0.wp.com/latex.php?latex=df_%7BX%7D%28%5Clambda%29+%3D+%5Ctext%7Btrace%7D%5BH_%7BRidge%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002)
which represents the effective degrees of freedom under the regularization parameter . In this context, it gives a measure of how much “influence” the model retains under , and ranges from zero to the number of predictors of . Generally the trace operation in this formula is a way to sum up those influences across all predictors, providing a single value that reflects the model’s complexity under the given level of regularization.
A Broad Speculation
Now, lets pivot our discussion about degrees of freedom to a broader context, which for sake of variety and depth, we’ll refer to by its other name: Tikhonov Regularization. We are given a more generalized formula:

where  represents the Tikhonov matrix. In the specific case of Ridge Regression, this matrix simplifies to
represents the Tikhonov matrix. In the specific case of Ridge Regression, this matrix simplifies to  . This perspective is instrumental in analyzing the impact of the regularization on our model, particularly through the matrix
. This perspective is instrumental in analyzing the impact of the regularization on our model, particularly through the matrix  .
.
Upon following standard mathematical procedures, we deduce:

This gives us room to speculate. Notably, is a symmetric matrix, suitable for decomposition:

In this eigendecomposition, the orthogonal matrix  can be perceived as an eigenbasis for the weight vector
can be perceived as an eigenbasis for the weight vector  , providing a foundation to understand how each dimension contributes to the regularization. The eigenvalues in
, providing a foundation to understand how each dimension contributes to the regularization. The eigenvalues in  offer a way to fine-tune this regularization optimally.
offer a way to fine-tune this regularization optimally.
This approach illuminates a novel aspect: generalizing the concept of degrees of freedom to assess the contribution of features in the model. We express this as:
![D(\Lambda) = \text{trace}[H_{Tikhonov}]](https://s0.wp.com/latex.php?latex=D%28%5CLambda%29+%3D+%5Ctext%7Btrace%7D%5BH_%7BTikhonov%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002)
![= \text{trace}[X(X^{T}X + \Gamma^{T} \Gamma)^{-1} X^{T}]](https://s0.wp.com/latex.php?latex=%3D+%5Ctext%7Btrace%7D%5BX%28X%5E%7BT%7DX+%2B+%5CGamma%5E%7BT%7D+%5CGamma%29%5E%7B-1%7D+X%5E%7BT%7D%5D&bg=ffffff&fg=242424&s=0&c=20201002)
where  now represents a more comprehensive measure of the model’s flexibility, factoring in the influence of each predictor variable as denoted by the eigenvalues
now represents a more comprehensive measure of the model’s flexibility, factoring in the influence of each predictor variable as denoted by the eigenvalues  . This generalized definition of degrees of freedom is a significant stride in understanding the intricate balance between feature contribution and regularization in complex models.
. This generalized definition of degrees of freedom is a significant stride in understanding the intricate balance between feature contribution and regularization in complex models.
